MainPage/Computer Vision/Lecture/2-5 RAW
语音识别:Youtube 转文本
断句与标点:chatGPT 4o
翻译:chatGPT 4o
2.5 Основные методы оптимизации градиентного спуска
基本梯度下降优化技术

Ни для кого не секрет, что самый распространённый метод обучения нейронных сетей — это градиентный спуск. В общем виде правило обновления весов модели представлено на слайде. Теперь параметр отвечает за величину шага; его принято называть скоростью обучения. На самом деле, в представленном виде данный метод практически не применим в современных задачах глубокого обучения в силу целого ряда причин. К примеру, для того чтобы сделать всего один шаг по методу градиентного спуска, то есть сделать всего одно изменение параметров сети, необходимо подать на вход сети последовательно абсолютно весь набор обучающих данных. Затем для каждого объекта обучающих данных вычислить ошибку и рассчитать необходимую коррекцию коэффициентов в сети, но данную коррекцию не применять, и уже после подачи всех данных рассчитать сумму корректировок каждого коэффициента сети, то есть сумму градиентов, и произвести коррекцию коэффициентов на один шаг. Очевидно, что при большом наборе обучающих данных такой алгоритм будет работать крайне медленно.
众所周知,神经网络最常见的训练方法是梯度下降法。总体而言,模型权重更新规则如幻灯片所示。现在,参数负责步长的大小;这个参数通常被称为学习率。实际上,在现代深度学习任务中,这种形式的梯度下降法几乎不可应用,原因有很多。例如,为了进行梯度下降的一步,即只对网络参数进行一次更改,必须依次将整个训练数据集输入网络。然后,对于每个训练数据对象,计算误差并计算出所需的权重修正,但这些修正并不立即应用。只有在输入所有数据后,计算每个权重修正的总和,即梯度总和,才进行一次性修正。显然,对于大型训练数据集,这种算法将非常慢。
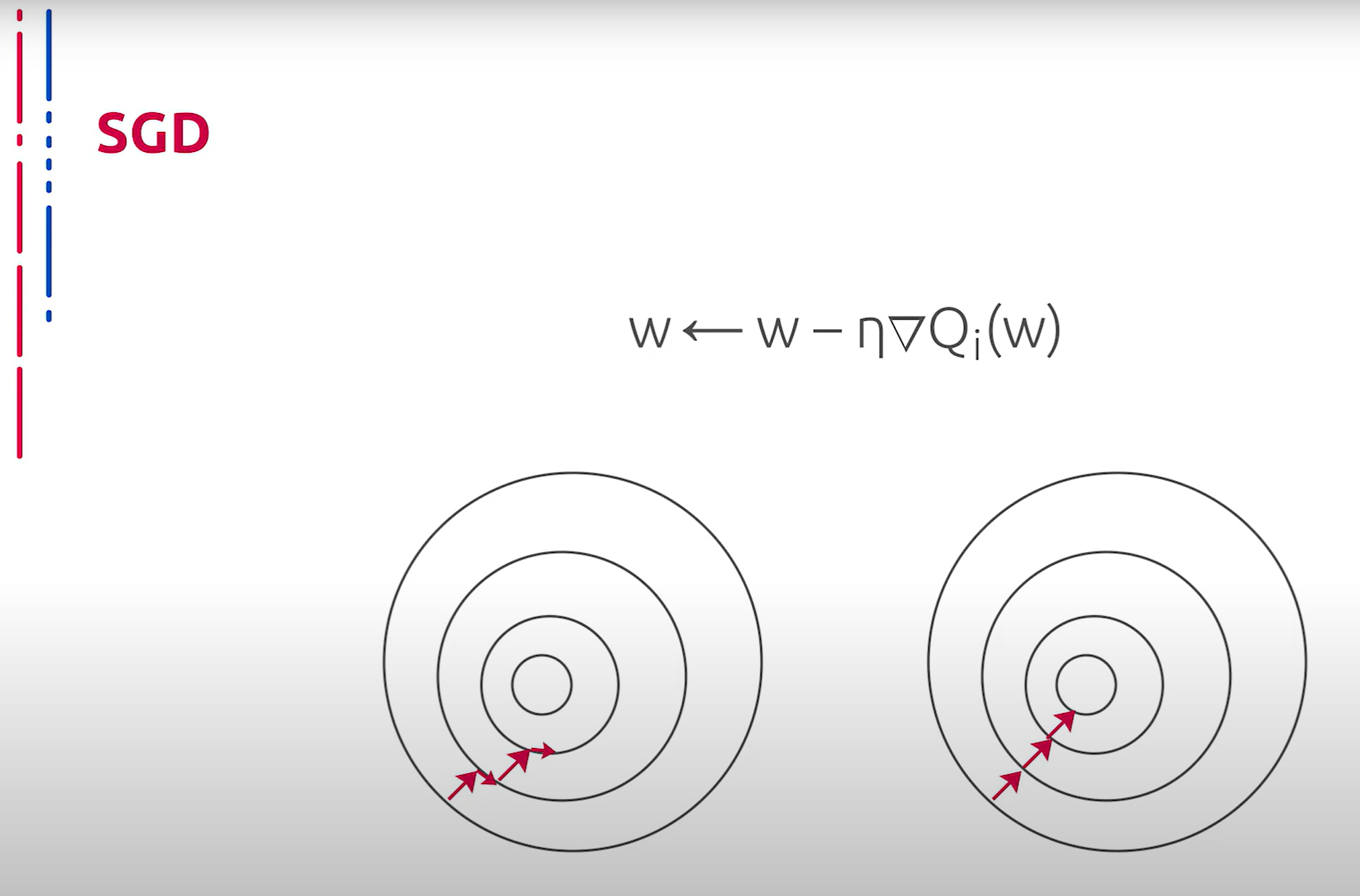
Для того чтобы исправить упомянутую ранее проблему, применяется концепция стохастического градиентного спуска. Подобная идея ускорения алгоритма заключается в использовании только одного элемента либо некоторой подвыборки для подсчёта нового приближения весов. При этом процесс обучения глубоких архитектур на реальных наборах данных ускоряется настолько, что становится возможным. Из прочих достоинств этого метода можно отметить также простоту реализации и применимость для задач с большими данными, то есть иногда можно получить решение даже не обработав всю выборку. Но нельзя не сказать пару слов о недостатках, среди которых отсутствие универсального набора эвристик для выбора элементов. Таким образом, данные стратегии лучше строить для конкретной задачи отдельно. В рамках обучения классификатора обычно используется выбор элементов из различных классов.
为了解决上述问题,引入了随机梯度下降的概念。这个加速算法的想法是仅使用一个元素或某个子样本来计算新的权重近似值。这使得在真实数据集上的深度结构训练过程加快,变得可行。除此之外,这种方法的优点还包括实现简单,适用于大数据任务,即有时即使未处理整个数据集也能获得解决方案。但也不得不提及一些缺点,其中包括缺乏选择元素的通用启发式方法。因此,这些策略最好针对具体任务单独构建。在分类器的训练中,通常使用来自不同类别的元素选择方法。
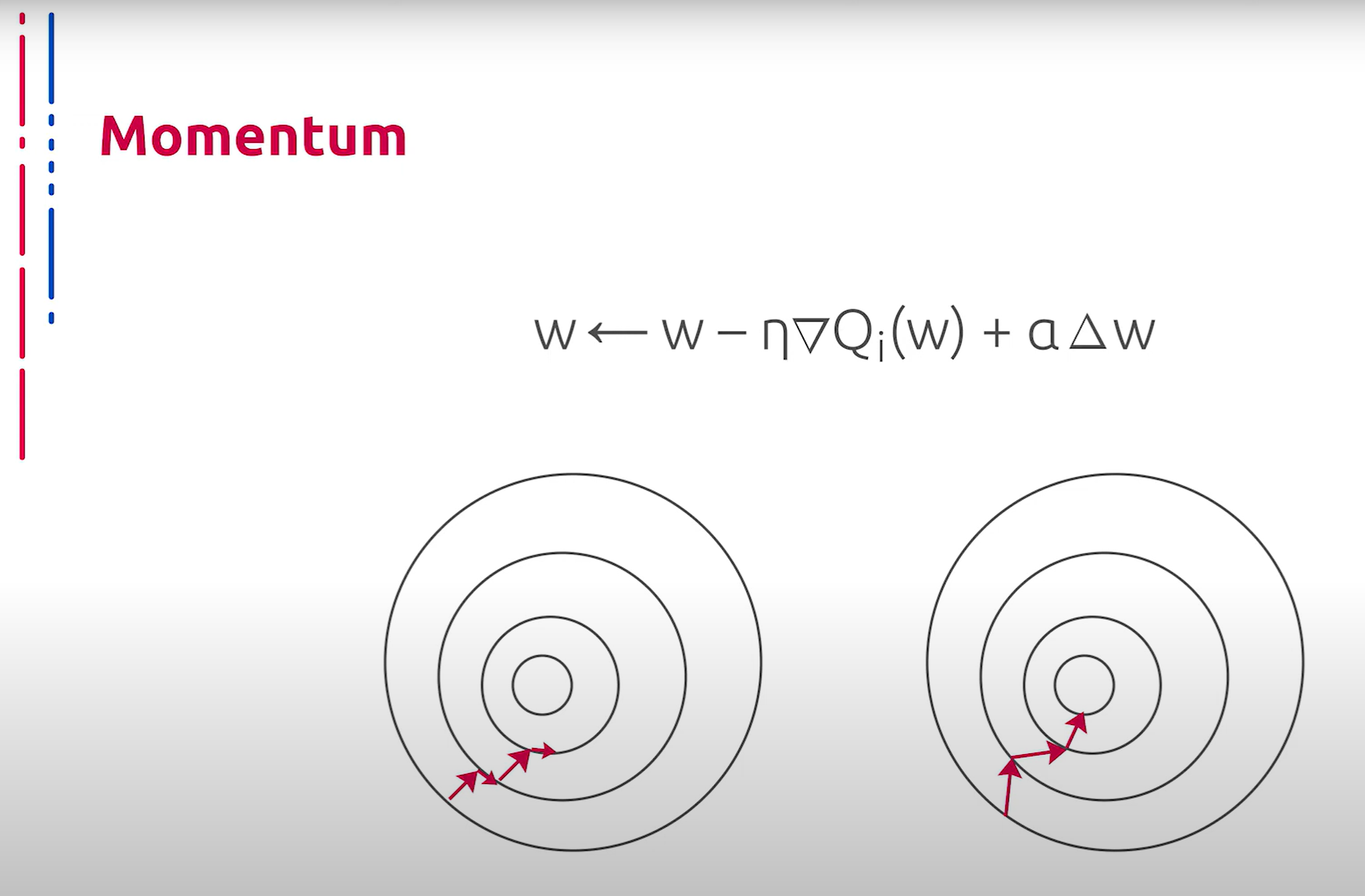
Рассмотрим далее некоторые усовершенствования стохастического градиентного спуска. Первым из них является метод импульсов. Данный алгоритм запоминает изменения Δw на каждой итерации и определяет следующее изменение в виде линейной комбинации градиента и предыдущего изменения. Нетрудно догадаться, что данная оптимизация уходит корнями в физику. В отличие от классического стохастического градиентного спуска, метод пытается сохранить продвижение в том же направлении, предотвращая колебания.
接下来我们讨论一些随机梯度下降的改进方法。首先是动量法。该算法记住每次迭代中的Δw变化,并将下一次变化确定为梯度和前一次变化的线性组合。不难猜测,这种优化方法源于物理学。与经典的随机梯度下降法不同,该方法尝试保持在同一方向上的前进,防止振荡。

Теперь рассмотрим одни из самых часто применяемых и демонстрирующих в общем случае лучшие эмпирические результаты усовершенствованные методы стохастического градиентного спуска. Первый из них — RMSProp. Основная идея данного подхода заключается в накоплении истории обновлений параметров для уменьшения реакции весов по наиболее часто изменяющимся при обновлении направлениям. Причём наибольшее внимание в истории обновлений уделяется именно последним изменениям параметров, таким образом уменьшается значимость общего фона данных и подчеркиваются наиболее редкие, вследствие чего значимые направления обновления.
现在让我们看看一些最常用并且通常表现出最佳经验结果的随机梯度下降改进方法。第一个是RMSProp。该方法的基本思想是通过累积参数更新历史,减少权重对更新中最频繁变化方向的反应。历史更新中最关注的部分是最新的参数变化,这样就减少了数据整体背景的重要性,突出了最稀有的变化,从而显著的更新方向。

Adam развивает идею RMSProp ещё дальше. Помимо накопления и сокращения движения в наиболее частых направлениях изменения градиента посредством сокращения второго момента, путём накопления первого момента стимулируется движение в направлении глобального улучшения. Данное сочетание стратегий даёт очень хороший результат и по умолчанию рекомендуется использовать Adam для оптимизации весов глубоких нейросетей, если, конечно, нет никаких известных причин против.
Adam进一步发展了RMSProp的思想。除了累积和减少梯度变化最频繁方向的运动,通过累积第一动量,Adam激励了在全局改进方向上的运动。这种策略的结合效果非常好,默认情况下推荐使用Adam来优化深度神经网络的权重,除非有已知的反对理由。